
Introduction
-
We hope to predict whether the people on Titanic is survival or not. This data is from website ''kaggle''. Actually, there are lots of method solve this problem and make a good prediction, for example, logistic regression. Hence, in this project we just predict it by the tool which we learned in the ML class.
Feature Engineering
In this section, the basic feature engineering will be introduced. The following analysis provides a simple base for prediction.
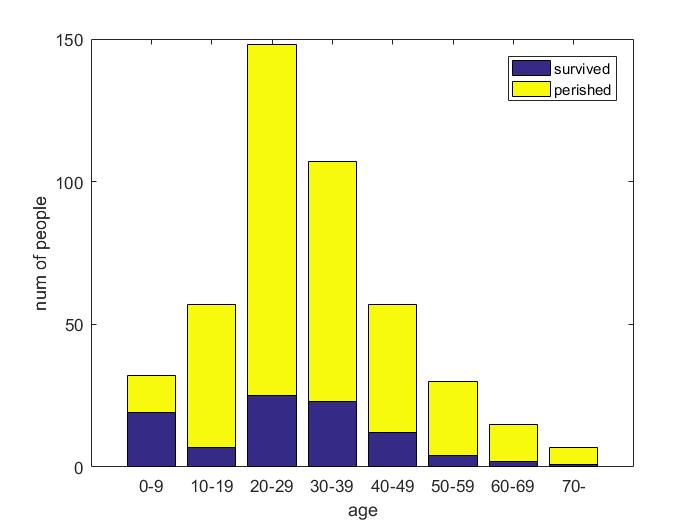
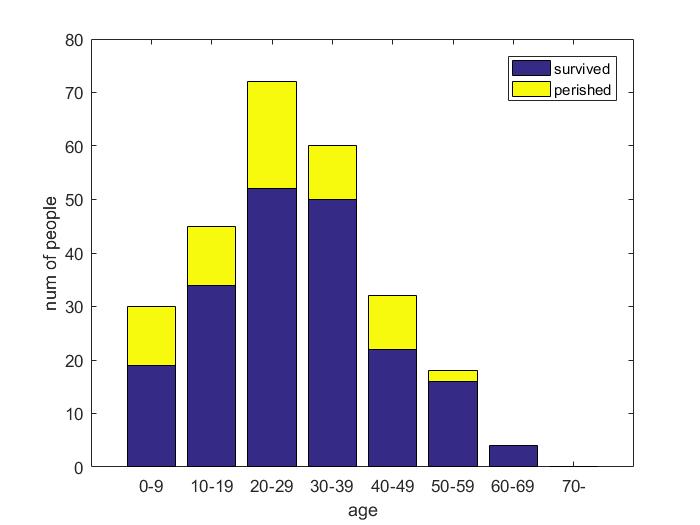
| Parameter | Female | Child |
|---|---|---|
| Accuracy | 0.7655 | 0.7703 |
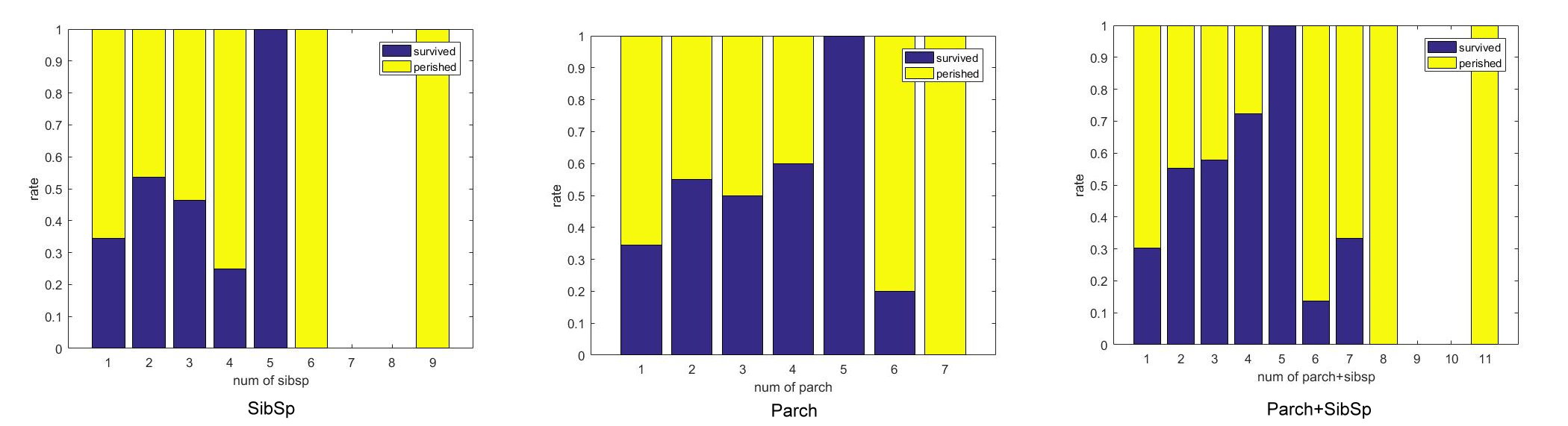
| Parameter | Female | Child | Female, Child and Family size |
|---|---|---|---|
| Accuracy | 0.7655 | 0.7603 | 0.7464 |
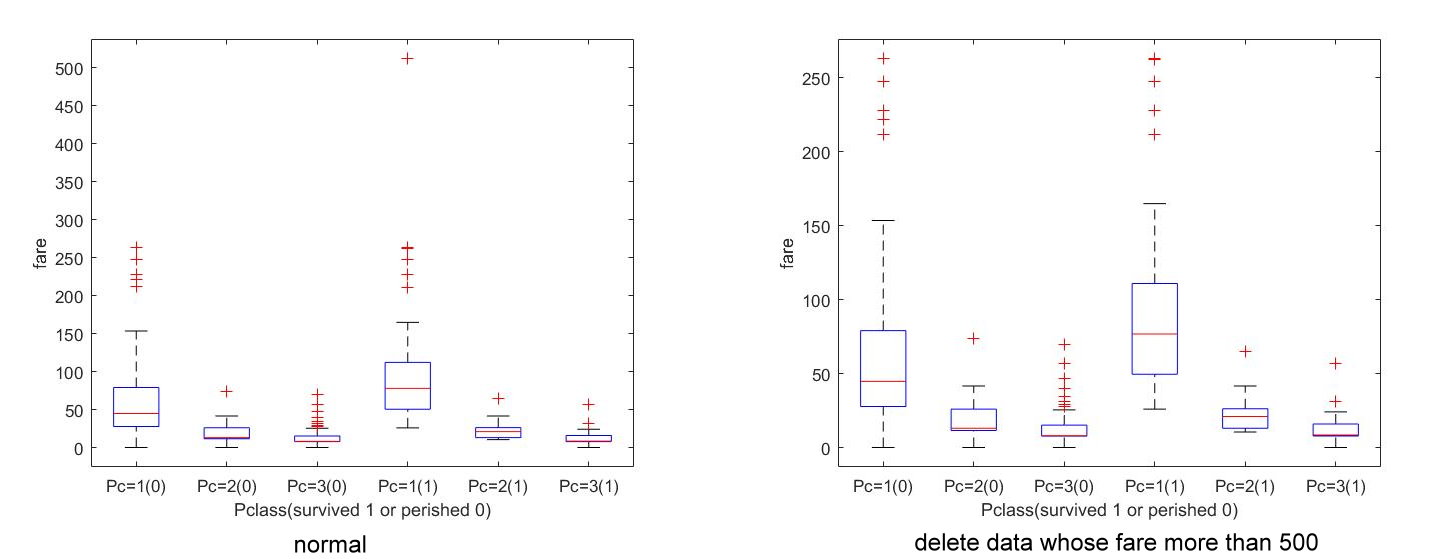
| Pclass | 1 | 2 | 3 |
|---|---|---|---|
| number of survival people | 136 | 87 | 119 |
| number of perished people | 80 | 97 | 372 |
Logistic Regression
If we choose the original parameter, by logistic regression, the following p-value can be gotten. We can deduce that survival have low relation with Parch, Fare and Embarked.
| Parameter | Pclass | Sex | Age | SibSp | Parch | Fare | Embarked |
|---|---|---|---|---|---|---|---|
| p-value | 0.0000 | 0.0000 | 0.000 | 0.0015 | 0.3199 | 0.2703 | 0.4230 |
Then, we choose the previous artificial parameter, e.g. child, family size and fare times Pclass.
| Parameter | Pclass | Sex | Age | SibSp | Family size | Fare*Pclass | Child |
|---|---|---|---|---|---|---|---|
| p-value | 0.0000 | 0.0000 | 0.000 | 0.1760 | 0.2452 | 0.1337 | 0.9861 |
PCA
We use PCA to reduce dimension of original original, i.e. Pclass, Sex, Age, SibSp, Parch, Fare, Embarked. Then, how many eigenvector is taken is chosen by logistic regression.
| eigenvector | 1st | 2nd | 3rd | 4th | 5th | 6th | 7th |
|---|---|---|---|---|---|---|---|
| p-value | 0.0000 | 0.0000 | 0.0000 | 0.0035 | 0.0021 | 0.9986 | 0.0000 |
Hence, let \(\mathcal{C}\) be the first 2 vector, \(\mathcal{D}\) be the first 3 vector and \(\mathcal{E}\) be the first 3 vector and the last vector.
Experience
Because we could check answers only few times, we choose the radial bump kernel which is recommended on website, first.
Train an SVM classifier using the radial basis kernel. That is,
subject to \(\alpha_j\geq 0\) and \(\sum y_i\alpha_i=0\)
| method | origin | \(\mathcal{A}\) | \(\mathcal{B}\) | \(\mathcal{C}\) | \(\mathcal{D}\) | \(\mathcal{E}\) |
|---|---|---|---|---|---|---|
| accuracy | 0.76555 | 0.77272 | 0.76794 | 0.70813 | 0.77511 | 0.77511 |
Only method \(\mathcal{C}\) is not higher than just use female to predict. Then, we focus on method \(\mathcal{B}\), i.e. {Pclass, Sex, Age, SibSp, Fare*Pclass} and classify them by other method in our class.
Choose soft margin SVM with 1 norm \(\min\frac{1}{2}\|w\|_{2}^{2}+C\|\xi\|_{1}\) and observe the over-fitting problem. The problem become that
subject to \(0\leq\alpha_j\leq C\) and \(\sum y_i\alpha_i=0\), for some \(C\).
| \(C\) | 1 | 0.1 | 0.05 | 0.01 |
|---|---|---|---|---|
| training accuracy | 0.7868 | 0.7868 | 0.7868 | X |
| testing accuracy | 0.7655 | 0.7655 | 0.7655 | X |
Note that “X” means classifier doesn’t learn anything i.e. every \(\alpha_j\) is zero.
Choose soft margin SVM with 2 norm \(\min\frac{1}{2}\|w\|_{2}^{2}+\frac{C}{2}\|\xi\|^2_{2}\) and observe the over-fitting problem again. The problem become that
subject to \(\alpha_j\geq 0\) and \(\sum y_i\alpha_i=0\), for some \(C\).
| \(C\) | 1 | 0.1 | 0.01 |
|---|---|---|---|
| training accuracy | 0.7991 | 0.7969 | 0.7935 |
| testing accuracy | 0.7655 | 0.7703 | 0.7727 |
According to above table, although the cross of two accuracy cannot be seem, it is a little over-fitting.
In class we learned SSVM, so we download SSVM matlab code from website “http://dmlab1.csie.ntust.edu.tw/downloads/”. Then, we got accuracy is 0.76555.
References
- Yuh-Jye Lee, Machine Learning Lecture Note, NCTU(2017)
- Eric Lam and Chongxuan Tang, CS229 Titanic–Machine Learning From Disaster
- Yuh-Jye Lee and Olvi L. Mangasarian. SSVM: A Smooth Support Vector Machine for Classification
Acknowledgements
Thanks my classmates Yuehchou Lee and Chunyen Huang. I would like to thank Dr. Lee for the guidance and encouragement.