
Introduction
The purpose is to accelerate the speech algorithm by parallelism using multiple GPUs. The algorithm given by speech group in IBM Thomas J. research center is about converting the word to spectrum, including three models: (i) encoder, (ii) decoder and (iii) post process, as shown in following figure.

Goal
This study accelerated the speech algorithm by data parallelism. The analysis discusses some challenges and how they are addressed. The following is research method:
-
Data Parallelism: Add data parallelism, maximize the GPUs utilization and find the bottleneck which reduced the utilization of GPUs.
-
Analysis: Analyze each function and accelerate it further and find the bottleneck function.
Results
- The function ‘‘trainloader’’ block the communication between CPU and GPUs.
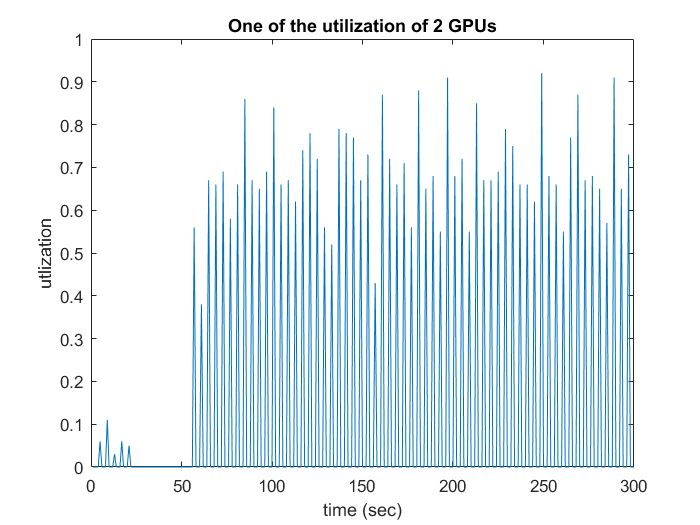
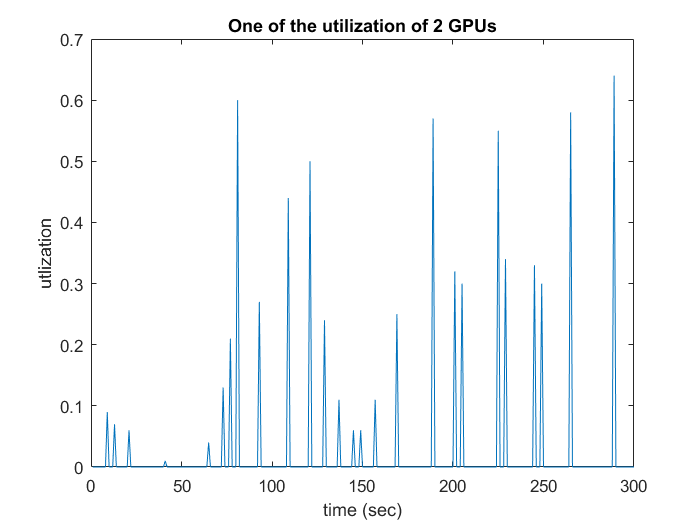
Figure: Comparison with and without function ''trainloader''. By the way, The function ‘‘trainloader’’ is to sort the data before generation.
- In order to verify the bottleneck, observe the performance without the function ‘‘trainloader’’, when using more GPUs. As shown in following figure, utilization of one GPU is improved when we use more GPUs.
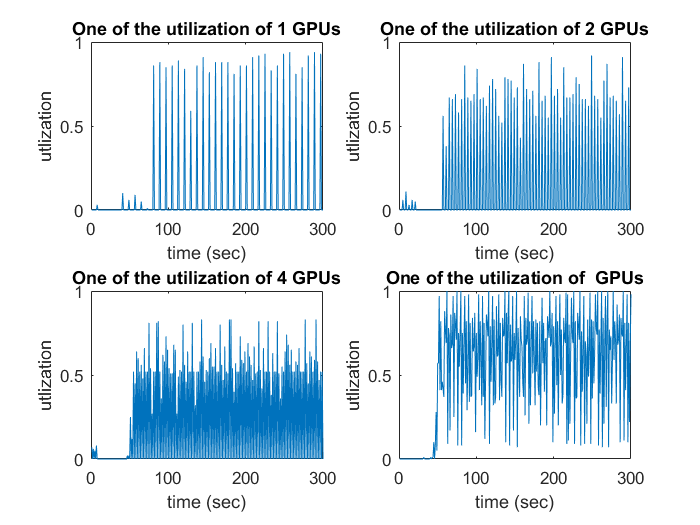
Figure: Comparison utilization of one GPU in different number of GPUs. - Removing the function ‘‘trainloader’’, observe the performance of each function. The following figure shows the relation between the GPU utilization and the training time taken in each function. The performance is improved, except for function ‘‘decoder’’ and ‘‘postproc’’.
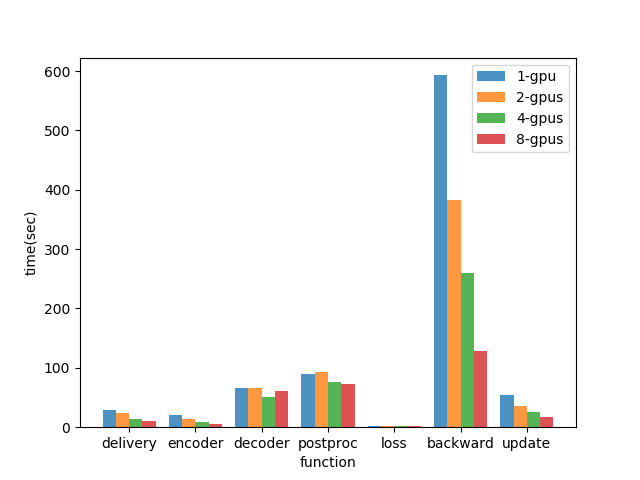
Figure: Comparison each function in different number of GPUs.
References
- A. Rosenberg, A. Sethy, B. Ramabhadran and M. Picheny, End-to-end Speech Recognition and keywords search on low resource language.
Material
Acknowledgements
I sincerely thank my advisor Dr. Rosenberg, Dr. Chung and Dr. Chen for the guidance and encouragement. Also, I would like to thank Dr. Wang for this intern opportunity at IBM Research.